
“Egyptian Hieroglyphs Segmentation with Convolutional Neural Networks” a research by Tommaso Guidi, Lorenzo Python, Matteo Forasassi, Costanza Cucci, Massimiliano Franci, Fabrizio Argenti, and Andrea Barucci has been selected as cover story on Algorithms, Volume 16 Isse 2.
We had the chance to talk with Andrea Barucci, one of the authors of this paper, who is researcher at the “Nello Carrara” Institute of Applied Physics CNR – IFAC and our fellow.
Would you explain briefly the origin of your study “Egyptian Hieroglyphs Segmentation with Convolutional Neural Networks” and its main focus?
The idea comes from a “transfer learning” from applications in Radiomics (Clinical Imaging) and it was born during a conversation with a friend working in Egyptology. We started this research with the aim to translate small pieces of hieroglyphs, but then the feedback we got from Egyptologists was that it was a very complex task and maybe too ambitious. This suggestion led us to move our research towards the transliteration, which is the phase that precedes translation. This means that we applied our methods to recognizing each single symbol, instead of trying to understand the meaning of images including more hieroglyphs, for which we didn’t have enough data. So, this will be a future work in progress.
How many data are we talking about?
The first network, Glyphnet (GitHub), was trained using a dataset containing about 6000 hieroglyphics. The second network instead was the well-known framework Detectron2, developed by the Facebook AI Research Group to perform segmentation of image instances, was trained with 3000 examples.
What is the major surprise or the most interesting results you encountered in addressing this research?
The ability to recognize symbols just with a very shallow training! It was an amazing surprise to realize that the system we worked on it is performing very well even if the training dataset is not so big. This behaviour may suggest that the internal hidden layers of the network, for examples the layers deputed to recognize the edges of items and simple shapes, works well. This in my opinion can be ascribed to the generalization properties of the hidden layers of the CNN.
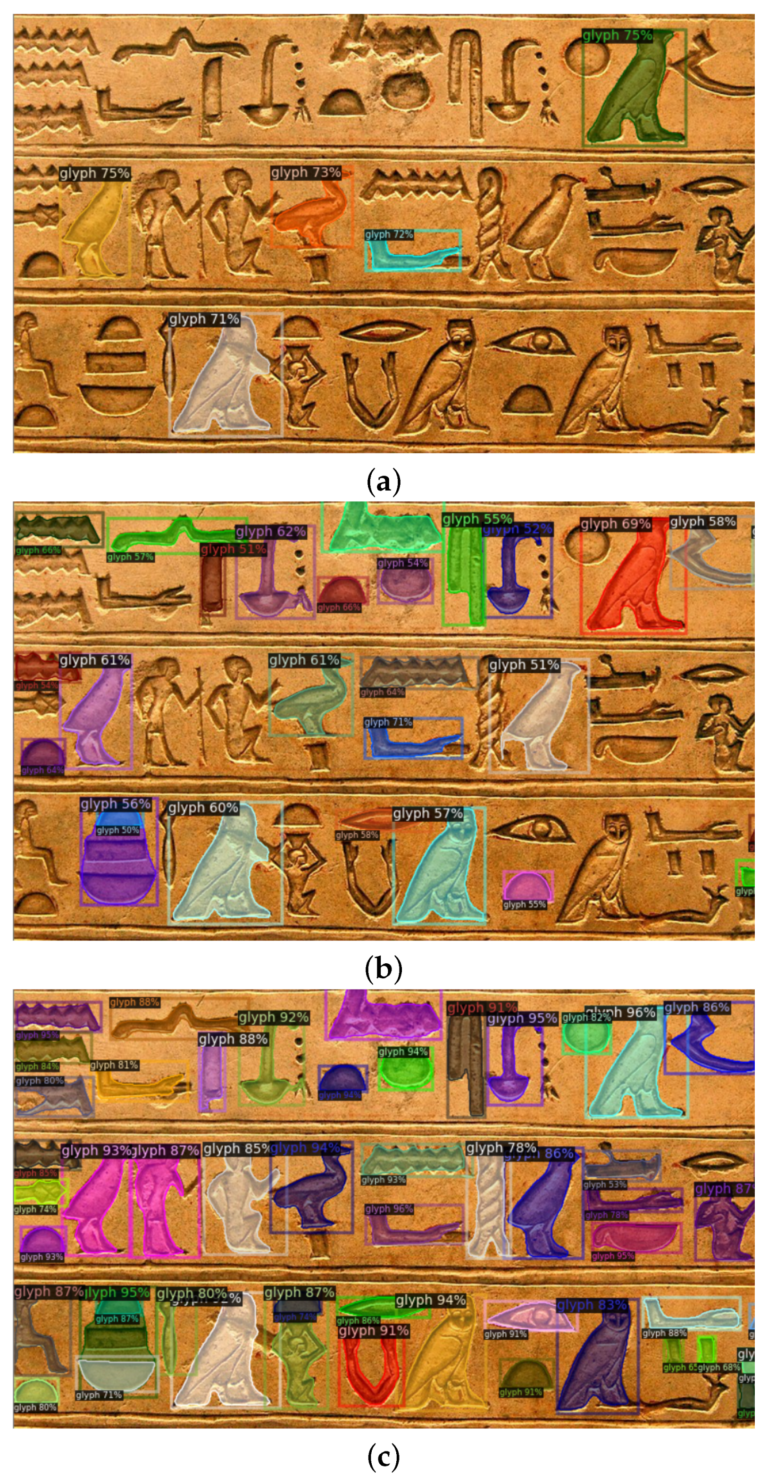
So can you explain what you did?
In this work we wanted to test the ability of Convolutional Neural Networks (CNN), a class of Neural Networks well-known in the field of Computer Vision, to face the problem of ancient Egyptian Hieroglyphs segmentation. The task was apparently not so easy, due to many factors such as the complexity of artifacts state of conservation or the high variability of documents. Leveraging on our experience in the field of medical imaging we decided to use the Detectron2 framework, in particular a kind of CNN known as Mask R-CNN, which are usually well suited for task segmentation in complex images. So, we trained this network using a specific developed dataset of images including many hieroglyphs inside.
In segmentation, the task is to assign to every pixel in the image to a particular category, such as cat, dog, car or background. In our specific case the task was to assign every pixel to a specific class of hieroglyphs. It is worth to note that hieroglyphs are represented by a wide spectrum of ideograms. Using the Gardiner signs list we have 26 categories for about 1071 symbols [classes]. These symbols are combined to give words and sounds. Moreover, they could be written in different ways, such as monumental [used in this study] or hieratic, depending on situations and/or on the historical age; different directions such as right to left, left to right, top to bottom; different supports such as papyrus, wood and stone.
What are the major challenges you had to face during this work?
The first problem we met was the creation of a suitable dataset in order to train our convolutional neural network to perform symbol segmentation. As a matter of fact, there are not publicly available labelled dataset of ancient Egyptian hieroglyphs. So, our first task was to create such a dataset, using pictures coming from different online museum archives around the world. For our work we decided to use images coming from the archive of the Egyptian Museum of Turin and from the MET of New York.
The creation of such a dataset for instances segmentation, requires not only to have the picture but in addition the segmentation of all the hieroglyphs inside.
Deep Learning are data-hungry algorithms, this means that in order to obtain a model with a good predictive accuracy, the dataset size needed for the training requires a lot of examples (thousands or more). Unfortunately, it is impossible a priori to know the dimension of the dataset required. In our case we leverage on a dataset of about three thousands of hieroglyphs with their corresponding segmentations. Another important aspect to be taken into account regarding the dataset creation, is related to the problem that symbols can appear in different colors, dimensions, contrast, etc., and in addition they can be damaged. Moreover, symbols can be slightly different depending on the historical period; language changed through thousands of years leading to differences among periods. In order to overcame this difficulty, we should rely on Egyptologists with linguistic competences. (Not to mention the fact that we should take into consideration the possibility of orthographic errors!) So, how can we deal with all this variability in the dataset, in order to obtain a model with good generalization performances?
The answer is not so easy, and we are working on that. What we can say is that for the results showed in this article, we tried to build a dataset as homogeneous as possible containing 41 classes of symbols. We are aware that one the major limitation of our study is the dataset and we are working on this in order to improve the generalization capabilities of our model.
This study really is a journey into the material history of Ancient Egypt artifacts.
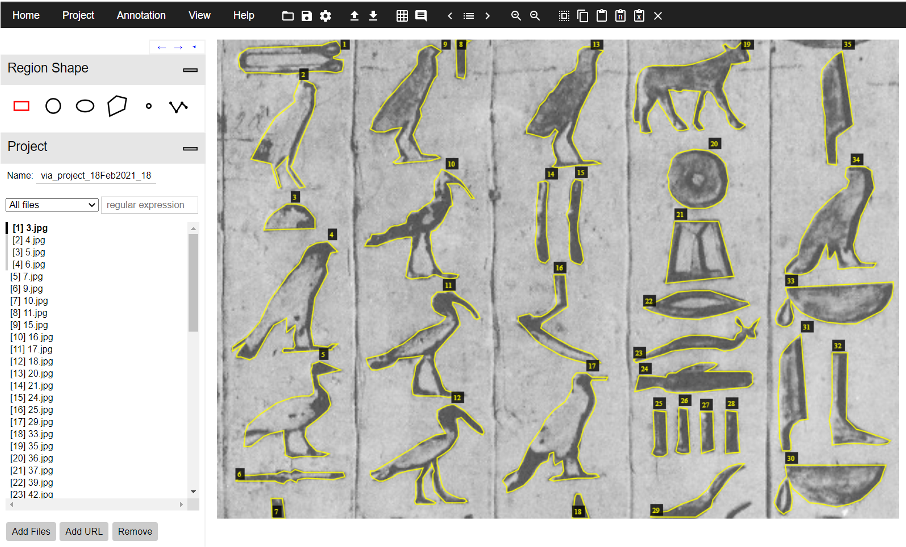
How does the training of CNNs works?
The CNN needs to see a lot of examples in order to be trained. So, first of all we feed the network with a bunch of known examples, this means the original images and the corresponding segmentation for all the hieroglyphs inside.
This can be a long computational work, taking days of training and test.
Where does the images come from?
Initially, for the case of the first CNN Glyphnet, we had a dataset made by a group of computer scientists and Egyptologists from Netherlands in 2012. Their dataset is publicly available and contains images from a stelae found in the pyramid of Unas. However, this assetset was not enough and not suitable for our work. We needed more samples and more important, each hieroglyph must come with its segmentation. So, we added to this dataset some images coming from the Egyptologist of our team: Massimiliano Franci from the Center for Ancient Mediterranean and Near Eastern Studies – CAMNES. In addition, we selected other images from important museum like the MET (which release its images in creative commons license, we appreciated it so much!) and from the Turin and Florence museums as well. I want again to highlight as every glyph needed to be manually segmented, requiring a lot of work and a lot of knowledge.
Would you like to give us a glimpse of future outcomes of this topic?
The main focus of this study was to understand if the Deep Learning was applicable in the field of hieroglyphics recognition and segmentation, aiming at the transliteration of symbols.
Now, after 3 years, we have other ideas! We are now working on a specific mixing of technology to enhance AI algorithms performances, hoping to publish during this year, so stay tuned.
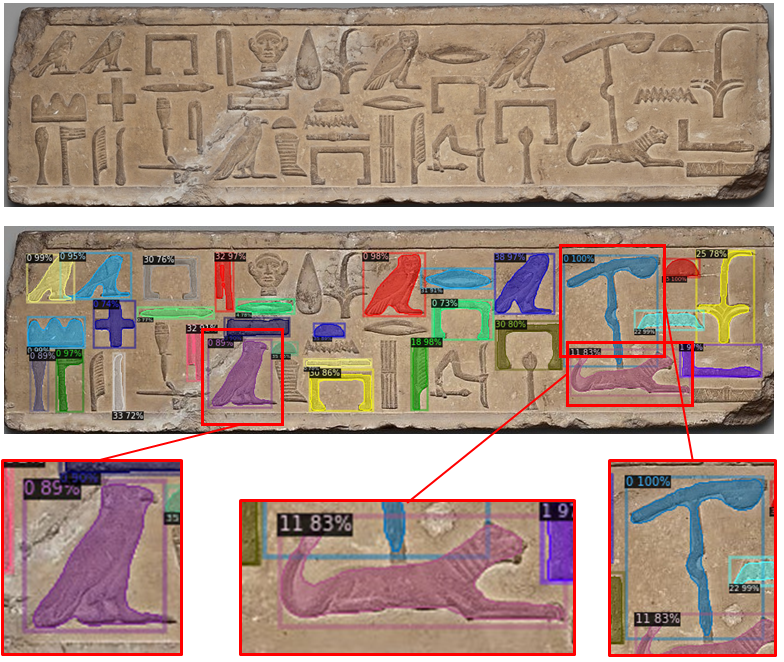
Top: original image;
Bottom: analysis results. Photo Credits: Tommaso Guidi, Lorenzo Python and Michela Amendola.
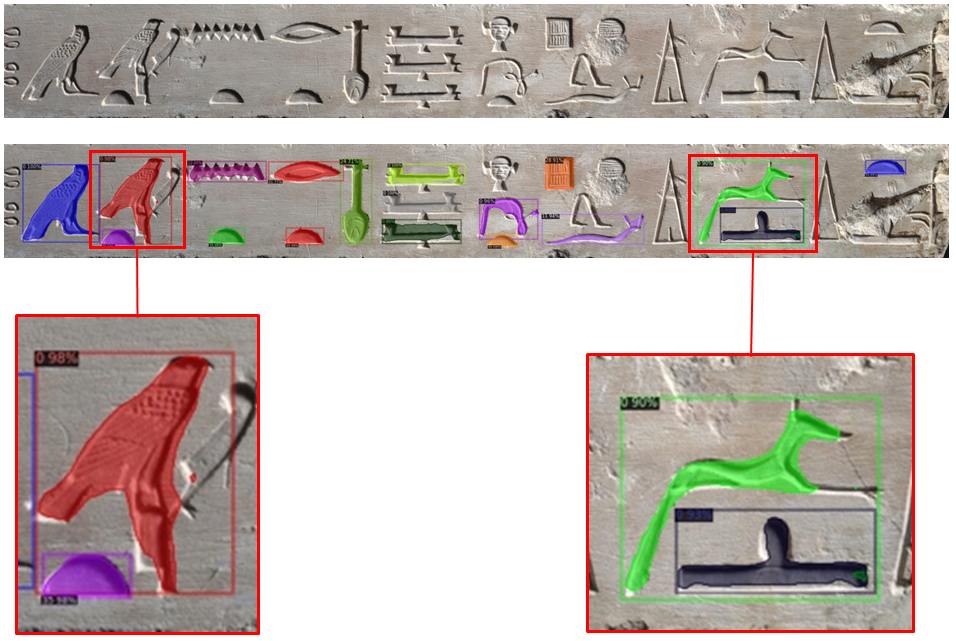
Photo Credits: Tommaso Guidi, Lorenzo Python and Michela Amendola.
Read the full article:
Guidi Tommaso, Lorenzo Python, Matteo Forasassi, Costanza Cucci, Massimiliano Franci, Fabrizio Argenti, and Andrea Barucci. 2023. “Egyptian Hieroglyphs Segmentation with Convolutional Neural Networks” Algorithms 16, no. 2: 79. https://doi.org/10.3390/a16020079
Andrea Barucci was our speaker at the 16th seminar of the D2 Seminar Series presenting this research.
The registration of the seminar is available through this link.